

If you’ve been keeping up, you already knew we added Glicko ratings to the ranking pages. Glicko is essentially a modern, more complex version of Elo, the tried and true rating system used mainly for chess, which we also feature two flavors of. To learn more about our adaptations, see the bottom of the FAQ. The “nuts and bolts” on the Glicko system can be found here.
As for Glicko, without getting into the weeds and trying to explain the differences that require a Mathematics PhD to really understand, to make a long story short, it has an additional variable called “rating deviation” that essentially equates to confidence — the lower the RD, the more proven a rating is. Furthermore, it outlines a protocol to increase rating deviation with inactivity. There’s also a more recent version of the system known as Glicko-2, which adds another variable called volatility.
Through thousands of test iterations, I’ve learned the unfortunate truth that rating deviation is fairly inconsequential for MMA, while volatility is absolutely worthless for MMA. This is part of the reason why I decided against bothering with Glicko-2. The other reason, is the added complexity. On a grander scale, it shows that I probably should’ve not bothered adding any variant of Glicko — especially since the author was not willing to provide guidance on tweaking some of factors to better accommodate MMA when I reached out to him about a year ago. That aside.. I’ve yet to find a system that can predict fight outcomes beyond a success rate in the high 60’s, Glicko included.
The main issue with combat sports and ratings systems are four-fold:
- Multitude of possible outcomes (decisions, submissions, knockouts, flukes, bad judges)
- Inconsistent fight schedules (varying inactivity length, inactivity reasons, crap matchmaking)
- Intangibles (location, weight divisions, varying rules, etc.)
- Result information (though, this is getting better)
Why did I bother? There comes occasions where I want to “prove” something… like hometown advantage or the real “worth” of a particular type of outcome vs. another. Of course, there’s the standard rating system in use here that I developed, but it is more of a gigantic flowchart converted into a software program than it is a mathematically pure, single formula and as a result, quite a bit tougher to incorporate changes into.
So, what’s on tap, first? Values of outcomes and their relevance…
If you read the FAQ, you’ll see that the outcome values for Glicko are currently scored for the winner as:
- draw -> 0.5
- split decision -> 0.667
- majority decision -> 0.833
- everything else -> 1.0
The logic = For a draw, each gets half-value because neither won or lost. For the winning decisions, this is based on the amount of scorecard(s) that each fighter received.
In any case where the winner’s value is less than 1.0, the winner can lose points.
For the standard system here, the scoring for outcome values isn’t as “cut and dry” to explain — again, think logic-based flowchart vs. PhD level math. BUT, if I were to convert to a similar scale as Glicko, it’d look something like:
- draw -> 0.5
- split decision -> (0.54 – 0.72) | typical -> 0.59
- majority decision -> (0.65 – 0.79) | typical -> 0.71
- disqualification -> 0.78
- unanimous decision -> (0.76 – 0.97) | typical -> 0.90
- KO/TKO/SUB -> (0.975 – 1.0)
Why the ranges? The standard Fight Matrix system observes rounds and scorecards. In the standard system, even though the outcome values are less than 1.0, the winner can only lose points in cases where the value is less than approximately 0.85 — disqualifications excluded. For the record, technical decisions are handled differently as well.
So, my two initial tuning goals for Glicko are:
- What outcome values yield the highest prediction rates for the various decision types?
- Should disqualifications be ignored or included, since the outcome value needs to be 1.0?
For #1, I looked at fights 2010-2019 in which both fighters had at least 4 fights each, prior to:
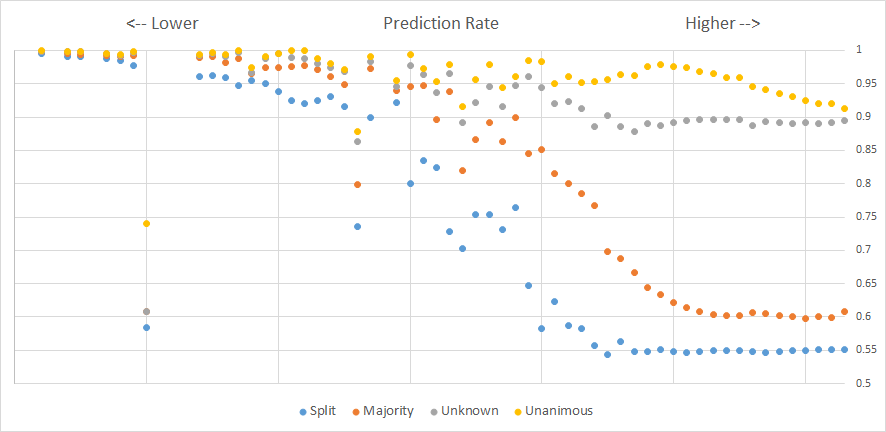
In the above graphic, each “dot” represents up to several hundred test iterations using the aforementioned dataset. Furthermore, “unknown” represents decisions for bouts that did not have further info (split, majority, unanimous). Beyond that, you can see here that the value for unanimous essentially mirrors our “typical” value for the standard system and that the split/majority are even lower, though admittedly, the standard system is not purely objective/prediction-based, so we have to keep up appearances.
The highest prediction rate for split decision was an outcome value of 0.55 — basically a draw.
You can get to that logic with the typical scorecards of a split decision, which are: 29-28, 28-29, 29-28. One fighter received 2 rounds from 2 judges and a 1 round from 1 judge. The math on that is 5/9 = 55.5%.
Majority decision weighs in at about 0.61. The typical majority decision is: 29-28, 29-28, 28-28. In this case, one fighter received 2+2+1.5. 5.5/9 is 61.1%. Pretty damn close again.
Unanimous weighed in at roughly 0.91. Again, the typical unanimous decision is: 30-27, 30-27, 29-28. (3+3+2)/9 = 88.8%.
Unanimous decisions happen frequently enough and the optimal outcome value is far enough away from 1.0, to suggest that in an extreme mismatch, the winner should probably lose points for not finishing the opponent — perhaps with the only exception being that the opponent does not get a single point from a single judge.
#2, Should disqualifications count at a 1.0 outcome value, or not at all?
Well, there’s no interesting chart to show here. Although there are a limited amount of disqualifications in MMA history, the prediction rate was a touch higher when they are completely ignored.
Conclusions
- In an outright “all or nothing” system, it’d be more accurate to score split and majority decisions as draws than as wins.
- Overall, judges are pretty good. I think there’s enough info here to use a scorecard-based outcome value like we already do with the standard system and maybe even take it a step further with Glicko by tossing the split/majority/unanimous completely out when scorecards are available. Admittedly, this is probably a bridge too far as non-UFC scorecard info is hard to find.
- Any fight that results in an unnatural end such as disqualifications may be candidates for banishment from rating.